




Your documents might include fragments of text which are not ordinary words or sentences - mathematical formulas, lists with technical abbreviations, fragments of code in a programming language, etc. Here is an example from a technical document explaining Windows messages:

These Windows messages are in coded or abbreviated form and are not proper English words. The Atlantis spellchecker naturally treats them as misspellings.
Such false reports can easily become distracting when many technical abbreviations are included in a document.
To avoid this, you could add all these abbreviations to your custom spellcheck dictionary. But this solution might very well be unacceptable if too many abbreviations need to be added to the lexicons, or if you simply do not want to add them to the lexicon permanently because you do not plan to use them in other documents.
Atlantis offers you a smarter solution for such situations.
Instead of adding tons of technical abbreviations to your custom dictionary, you can instruct Atlantis not to spellcheck the document fragment containing these abbreviations. This is done by marking the document fragment as belonging to the special <none> language. Any text fragment marked with the "<none>" language is ignored by the Atlantis spellchecker and by the other proofing tools of Atlantis (the AutoCorrect and hyphenation functions).
Here is how to proceed to mark a text fragment with the "<none>" language:


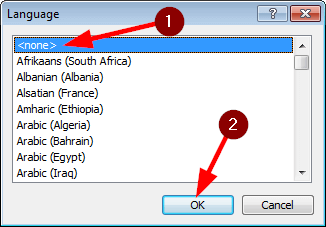
See also...



